
Introduction to Deep Neural Network Programming in Python
If there's one thing that gets everyone stoked on AI it's Deep Neural Networks (DNN). From Google's pop-computational-art experiment, DeepDream, to the more applied pursuits of face recognition, object classification and optical character recognition (aside: see PyOCR) Neural Nets are showing themselves to be a huge value-add for all sorts of problems that rely on machine learning.

I'm not here to teach you how these things work: there's a lot to it and there's a large part of the feature extraction that is still poorly understood, even by the people who design these things in the first place. Instead, I'm here to help the hapless Python programmer better understand a package I recently discovered and used in a project nolearn.
First of all, nolearn isn't just another DNN package - it's an abstraction layer on top of existing packages like
theano and lasagne that buries some of the raw coding in abstraction. It can be also be really frustrating to work with if
you don't have a Graphics Processing Unit, but it will work - you just have to be willing to run your RAM at max capacity for an
hour or two. I'll let you worry about installing nolearn and its dependencies - consider using virtualenv if you haven't used that before.
Ok, so I felt bad just saying "go install it on your own" when it's not as easy as pipping it or something. Try this in your venv:
pip install -r https://raw.githubusercontent.com/dnouri/nolearn/master/requirements.txt
pip install git+https://github.com/dnouri/nolearn.git@master#egg=nolearn==0.7.git
A Brief Example
To set up a simple network, you can do something like:
from lasagne import layers
from lasagne.updates import nesterov_momentum
from lasagne.nonlinearities import softmax
from nolearn.lasagne import NeuralNet
# SIZE = number of columns in feature matrix
# OUTPUTS = number of possible outputs (for binary classification this would be 2)
net1 = NeuralNet(
layers=[ # three layers: one hidden layer
('input', layers.InputLayer),
('hidden', layers.DenseLayer),
('output', layers.DenseLayer),
],
# layer parameters:
input_shape=(None, SIZE), # this code won't compile without SIZE being set
hidden_num_units=100, # number of units in hidden layer
output_nonlinearity=softmax, # output layer uses identity function
output_num_units=OUTPUTS, # this code won't compile without OUTPUTS being set
# optimization method:
update=nesterov_momentum,
update_learning_rate=0.01,
update_momentum=0.9,
regression=False, # If you're doing classification you want this off
max_epochs=400, # more epochs can be good,
verbose=1, # enabled so that you see meaningful output when the program runs
)
X_train, Y_train = load() # assuming you have some data you're training on here, removed for brevity
net1.fit(X_train, Y_train)
As you can see, nolearn is cool because it acts like sklearn does when you're modeling. There are, however, a few mysteries in this
code that you should be asking about:
- What is a "softmax"?
- What is "nesterov momentum"?
- Why are the learning rate and momentum set to those numbers?
- Why is regression set to
False?
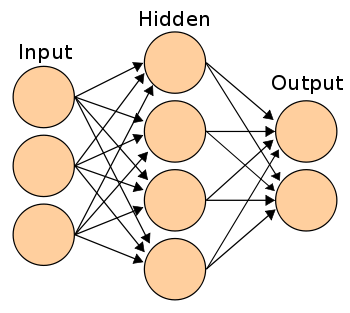
Softmax (and other output non-linearities)
This is implemented mostly out of convention because it works. There are a host of other non-linearities in lasagne and nolearn, but
this one is well studied and works well for classification problems in Neural Nets. If you want all the mathy details, Wikipedia is your friend
Nesterov Momentum and SGD in DNN
Like a lot of problems, Neural Nets benefit from a Stochastic Gradient Descent approach. Nesterov Momentum is just one of the concepts
of how to implement this, and apparently is a very popular method across applications. Feel free to experiment (and report back)
with others included in lasagne, like adagrad and rmsprop if you so choose.
You may notice a pattern with this: there's a lot of tinkering that can be done with Neural Nets. By all means, tinker, just know what to expect when you mess with things!
Parameter Tuning and Why Not To Do It
In my experience, messing with the learning rate and momentum just isn't worth it: you're more likely to improve performance if you mess with the overall structure of the neural net. These two parameters refer to the corresponding SGD parameters, a slow learning rate encourages incremental improvements, while a large momentum prevents getting stuck in local minima of the error surface. You're free to muck around with what these do, but be forewarned that if you just twiddle the knobs and hope for the best here, you're probably not going to get awesome results.
Regression
Regression and classification are separate tasks: don't ask your computer to do regression when you want classification, or vice versa. Bad things will happen, trust me
A More Complex Example (CNN)
I'll forgo some of the explanation here, and just point out a few things that you'll want to be wary of for CNN imlementations after presenting the code.
# SIZE = number of columns in feature matrix
# OUTPUTS = number of possible outputs (for binary classification this would be 2)
LE = LabelEncoder()
X_train, Y_train, X_test, Y_test = load()
# load data
# make sure data is in right format, & properly label-encoded
X_train = X_train.reshape(-1, 1, SIZE, SIZE)
X_test = X_test.reshape(-1, 1, SIZE, SIZE)
X_train, X_test = X_train.astype(np.float32), X_test.astype(np.float32)
Y_train = LE.fit_transform(Y_train).astype(np.int32)
Y_test = LE.fit_transform(Y_test).astype(np.int32)
model = NeuralNet(
layers=[
('input', layers.InputLayer),
('conv1', layers.Conv2DLayer),
('pool1', layers.MaxPool2DLayer),
('conv2', layers.Conv2DLayer),
('pool2', layers.MaxPool2DLayer),
('conv3', layers.Conv2DLayer),
('pool3', layers.MaxPool2DLayer),
('hidden4', layers.DenseLayer),
('hidden5', layers.DenseLayer),
('output', layers.DenseLayer),
],
input_shape=(None, 1, SIZE, SIZE),
conv1_num_filters=32, conv1_filter_size=(3, 3), pool1_pool_size=(2, 2), #these numbers can be changed as your please
conv2_num_filters=64, conv2_filter_size=(2, 2), pool2_pool_size=(2, 2), #these numbers can be changed as your please
conv3_num_filters=128, conv3_filter_size=(2, 2), pool3_pool_size=(2, 2), #these numbers can be changed as your please
hidden4_num_units=5000,
hidden5_num_units=5000, # Holy mother of layers, Batman!
output_num_units=OUTPUTS, #
output_nonlinearity=softmax,
update_learning_rate=0.01,
update_momentum=0.9,
regression=False,
max_epochs=20,
verbose=1,
)
model.fit(X_train, Y_train)
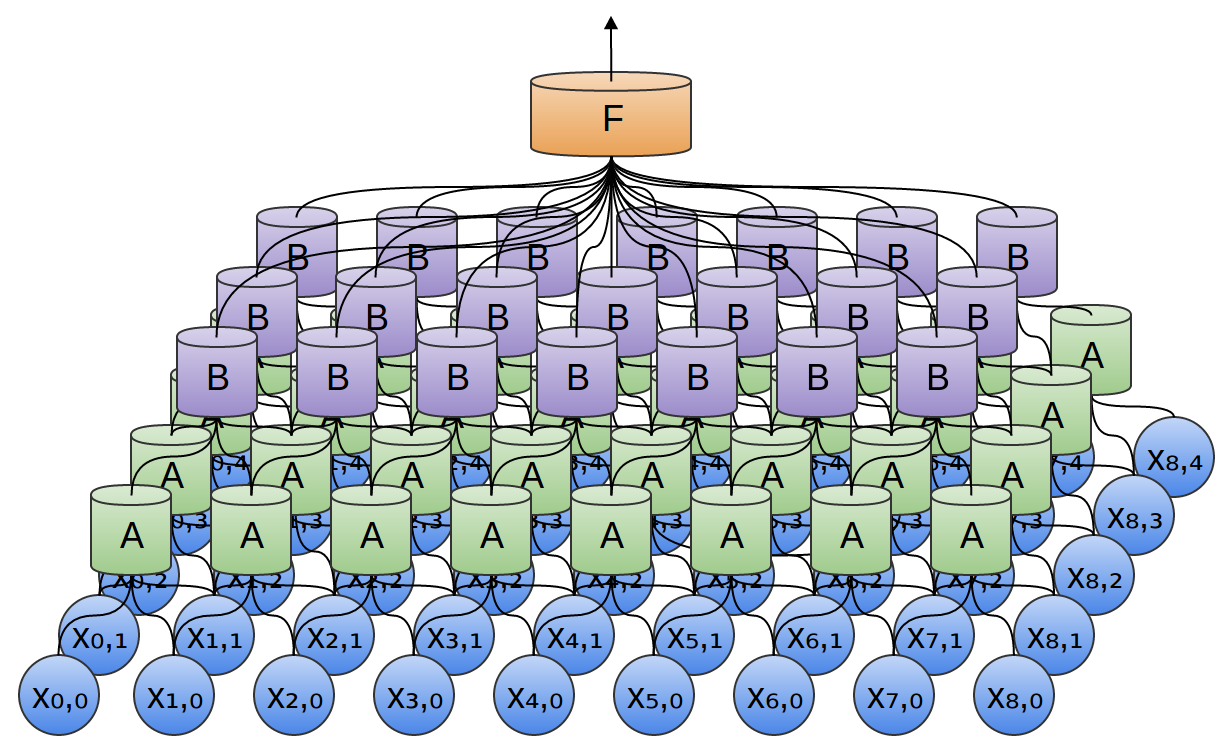
When To Use This
On images. CNN's really lack context for 1-D feature spaces. Notice that grayscale images are 2-D features in a 2-D feature space. You could probably do this with 3-D data as well, but that's harder to come by than simple image data.
Why We're Using Weird Input Dimensions
The short reason is that this is just how nolearn works with images. The reshape idea is that the first dimension is the number of
images in question, the second dimension is the number of color channels (1, in grayscale) and the last two are the (x, y) size of the input.
Square images are reccomended for sanity - you can't just go stuffing arbitrarily sized images into a CNN and expect sanity.
LabelEncoder() and Why You Should Use It
The module currently lacks support for string labels, so it's good to work around them using sklearn's LabelEncoder. It's also important that your inputs are in the right format - anything but float32/int32 can lead to the ultimate destruction of your CNN dreams.
Holy Layers, Batman!
This model is significantly more complex than the standard Neural Net. You should read Daniel Nouri's walkthrough of nolearn If you want to understand more about these layers and different configurations of them. As a sidenote: you'll realize upon reading Nouri's post that my post is very similar. His post is great, but it's also specific to a problem and I wanted to show how nolearn can be generalized - as well as explain some of the things that aren't addressed in his post.
A Note on Architecture
Whenever you want to deploy a Neural Net, keep architecture in mind. You can build willy-nilly things all day, but there should (ideally) be some reason you choose one Archictecture over another. See this journal article for a relatively easy to understand explanation of how/why certain DNN architectures are used. Interesting fact: CNN architecture (like what is shown above) is made to mimic how the human eye is believed to work! Cool!
Closing Thoughts
Please read this post for a more applied tutorial. This man does awesome work and I don't want to steal his post, but rather, give my readers a simple, boiled down version that they can play with. Sadly, there are some errors in Nouri's code that have been fixed by recent updates to his module, so cross check with this post if you run into any errors.